2026算法范式:AI算力结构的深层演进
美东时间近期,谷歌发布了一项名为TurboQuant的算法,这一技术在科技界引发了广泛讨论。该算法的核心在于通过数学手段对大型语言模型进行压缩,在保持精度的同时,显著降低了运行时的内存占用。这一现象不仅是单一技术的迭代,更是AI基础设施向高效能转型的重要信号。
算法的本质在于对数据几何结构的重构。TurboQuant通过PolarQuant方法,先对数据向量进行随机旋转,简化了数据的复杂性,随后利用QJL算法消除细微偏差。这种双阶段处理逻辑,实现了在不牺牲核心特征的前提下,对模型空间的极致压榨。从物理层面看,这直接缓解了键值缓存对内存的刚性需求。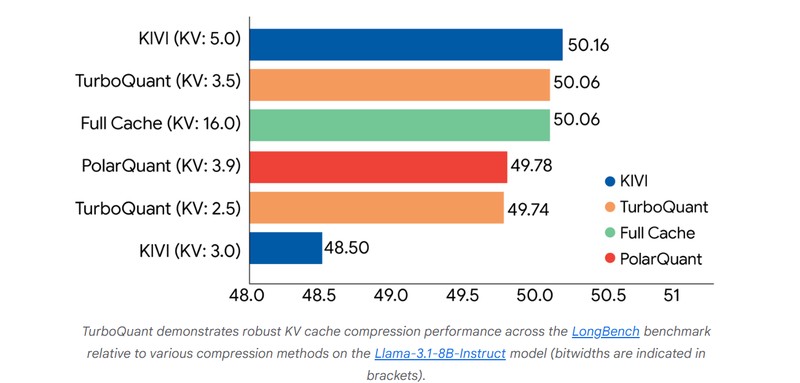
这种技术路径的出现,揭示了算力演进的一条客观规律。硬件产能的扩张终有极限,而算法效率的提升则具有近乎无限的潜能。当计算资源变得昂贵且稀缺时,软件层面的优化便成为打破瓶颈的关键杠杆。市场对于芯片板块的震荡反应,实则是对这一范式转移的预判,即未来AI发展的动力将更多转向软件优化与算法效率。
算法优化对算力生态的重构
软件算法的迭代往往比硬件制造的周期更具爆发力。当算法能够通过几何结构简化实现数据压缩时,底层逻辑便从单纯的硬件堆砌转向了数学效率的极致挖掘。这种转变意味着未来的算力增长将更多依赖于代码逻辑的精进,而非仅仅依靠晶圆产能的扩张。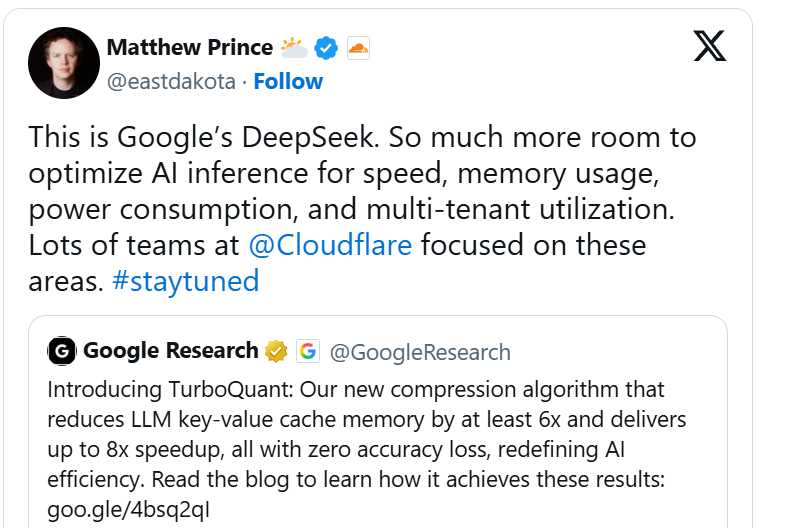
这种技术路径的切换,实际上是对资源配置效率的重新定义。在有限的内存边界内,通过算法优化提升数据吞吐量,本质上是将算力的天花板向上推移。这不仅降低了基础设施的维护难度,也为后续更复杂的模型训练腾挪出了宝贵的空间,形成了一种良性的技术循环。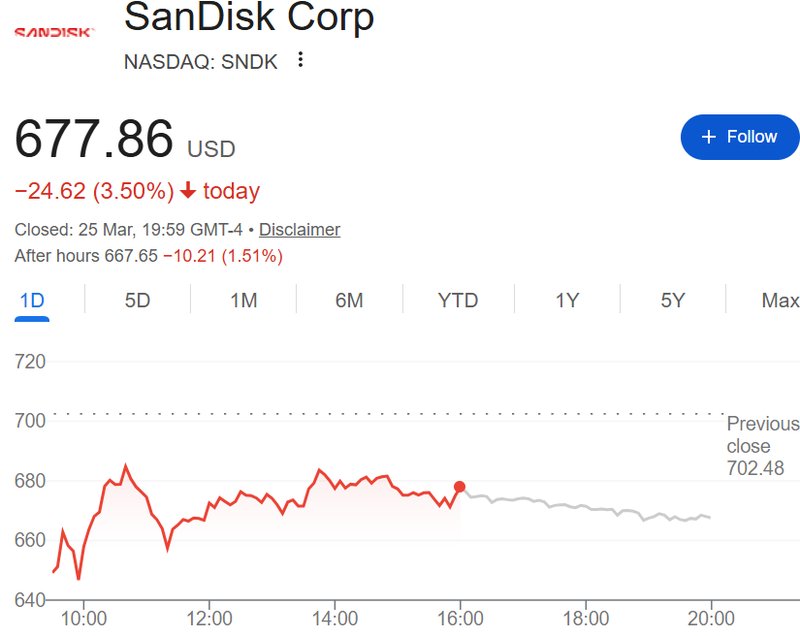
最终的产业形态将趋向于算法与硬件的深度耦合。企业不再单纯追逐硬件规模,而是转向追求单位算力产出的最大化。这种范式转移将促使整个AI产业链重新评估投入产出比,从而在更可持续的道路上实现技术跃迁。


